|
问题来自在看这篇博客时看到的图片
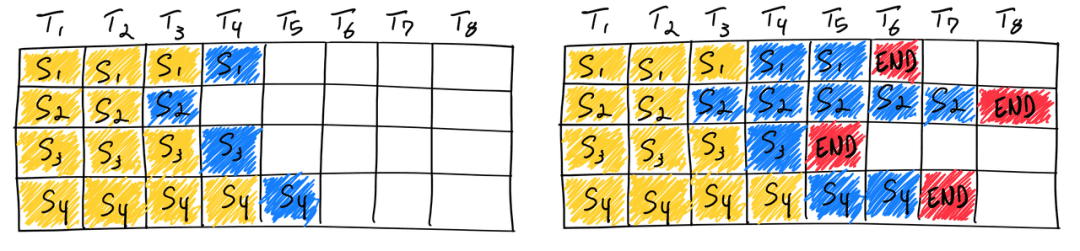
这张图片中是静态 batch 的示意图,但我的理解似乎有所偏差,希望有大佬能答疑解惑。
问题 1:对于静态 batch 场景,同一个 batch 中不同的 sample 的 prefill 是同时完成的吗?
我的理解:
对于一个单独的短 prompt ,prefill 阶段肯定是一个比很长的 prompt 快的。但是当这 2 个长度不同的 sample 经过 padding 然后拼成了一个静态 batch 之后,也就是维度变成了 [batch_size, ..] (当然这里可能不止 2 个 sample )。在 prefill 阶段,他们肯定是同时开始的,因为 transformers 内部是很多的矩阵乘法。并且要经过很多层,比如:
emb = layer1(emb)
emb = layer2(emb)
...
上面的 emb 的维度应该也都会是 [batch_size, ....]
虽然同一个 batch 之间不同 sample 单独做 prefill 需要的时间不同,但是当他们成为一个 batch 之后,变成了一个大矩阵,他们在经过不同的 layer 的时候,都是一起一层一层过的,也就相当于他们同时开始 prefill 阶段,然后同时完成 layer1, 同时完成 layer2, ......。最后一起完成最后一层,获得第一个预测的 new_tokens ( batch 中每个 sample 都有一个 new_token)。所以,在我的理解中,prefill 阶段应该是左右对齐的。
问题 2: 以下我对 Continuous Batch 的理解是否正确?
我的理解:
- 首先模型每次 forward 都是生成一个新的 token (无论是 prefill 还是 decoder 阶段)。prefill 完成生成第一个 new_token 后接着自回归。
- 如果是 continous batch 配置情况下,如果有 sample 输出 end_token ,那 batch_size 就少一个,可能就可以再放一个 sample 进来。这样子的话这个新 sample 要做 prefill (目的也是生成 new token ),别的 sample 是继续在 decoder 阶段。不过别的 sample 都是有前面的 kvcache 的,所以这个时候这个新 sample 的 prefill 就拖累了旧的 sample 中的 decoder 过程,毕竟大家都还是在一个 batch 中,大家最终还是一起一层 layer 一层 layer 过。
- 如果同一个 batch 都在 decoder 阶段,因为 kvcache 的存在大家都很快。但是只要有一个 sample 输出了 end_token, 就可能允许新的 sample 进来,这个新 sample 的 prefill 过程因为可能没有 kvcache 会拖累其他的 sample 。所以有一些工作提出要将 prefill 和 decoder 分离。
以上是我的理解,不知道有多少错误的内容,希望有大佬指正。我的描述可能有点啰嗦,抱歉。
| 


